板刷、按顺序 vp 和随机 vp 兼备。
#814
A
代价颇具构造性,可以拆成长为 \(1,2\) 的操作。
简单感受一下,会形成若干连续的异或和为 \(0\) 的连续段。
DP 或者贪心。
B
拆 Fibonacci 是经典的,考虑从高到低贪心。
那么,有 \(k\) 个数不过是用堆并行维护。
C
\[ \begin{align*} &\quad\; \max \left\{ \gcd(n, k) \sum_{i \equiv s \pmod{\gcd(n, k)}} a_i \middle\vert 1 \le s \le n, 1 \le k < n \right\} \\ &= \max \left\{ d \sum_{i \equiv s \pmod d} a_i \middle\vert 1 \le s \le n, d \mid n \right\} \\ &= \max \left\{ d \sum_{i \equiv s \pmod d} a_i \middle\vert 1 \le s \le n, dp = n \right\} \end{align*} \]
D [Coded]
通过笛卡尔树同构,转化为一个经典的二分图完美匹配的存在性问题(数轴上点与区间匹配)。
不过这个形式很特殊,我们可以直接贪心。
Hall 定理同时告诉我们(或者说,给我们以一定的直觉以发现),合法的 \(d\) 是一个区间。
正反各贪心一次即可得到上下界。
E [To code]
问题是找两个带边权二分图的一个同构,其中每个点连的边权值互不相同。
然后很谔谔地,搜索剪枝。
可以发现复杂度不超过某一侧点数乘边数,选取小的那侧就可以达到 \(O(nm \sqrt{nm})\)。
F [Coded]
莫反就不推了。关键显然是区间的质因子集合。
bitset 乱搞,或者根号分治乱搞。
简要介绍 dx 的 bitset 乱搞 /mgx。
直接用 bitset 维护 \([1, C]\) 每个数是否符合要求。那么询问就是每个出现过的质数的 bitset 的交/并。
对前 \(k\) 个质数考虑暴力预处理,结合 ST 表回答;以后的质数每个数只会有 \(O(\log_{p_k} m)\) 个,大部分时候可以是 \(O(1)\),然后猫树分治。
#810
A
手玩一下,每种颜色必然是相邻的两行或者两列。
B
先算出经过所有天的降雨量,然后简单维护一下即可。
C
记 \((x,y,z) = (a\oplus b, b\oplus c, c\oplus a)\),有 \(x\oplus y\oplus z=0\)。
那么由于异或是不进位加法,不构成三角形当且仅当有一对数的 \(1\) 无交。
数位 DP 即可。
D [To code]
从小区间合并到大区间,那么构造就很显然了。
思考:能否计数?也就是,单排列扩展到树上是否还能数?不过单排列本身就很困难了,感觉树上更困难。
E [To code]
好像是原题。
为了方便,\(a,b\) 先非严格升序。
二分答案,则得到一张共 \(1000 \times n \times m\) 个点的二分图。
二分图博弈的结论是,某个起点必胜当且仅当其为最大匹配的必须点。
- \(\implies\):注意到先手始终可以走最大匹配中的边。如果不满足,那么此时后手走过的也是一个同等大小的匹配,与起点是必须点矛盾。
- \(\impliedby\):注意到先手第一步就会走到最大匹配中的点。如果不满足,那么显然不是最大匹配。
接下来还要猜一个结论:\(1000\) 和 \(1\) 等价。
那么接下来就是要求解最大匹配了。
不知道 Hall 定理在这种问题上能不能起效果,但是这里考虑考察最大独立集。
那么考虑钦定原网格中每行每列选择的点是左部还是右部点,不难发现在行和列上也分别是选择一个前缀和后缀。
考虑枚举决策的位置,发现每一行的最优决策是凸、单峰的。那么直接做就可以了。
#808
A
显然有个分界线,随便做一下。或者倒着贪心。
B
单独处理 \(0\),然后暴力做。
C
MST 唯一,然后是类似换根的操作。
D
显然二项式反演,然后随便编个 \(O(n^2)\) DP 即可。
E [To code]
做法叙述起来很简单,主要就是一句话:
\[ f^k((l, r)) = \bigcup_{i=l}^{r-1} f^k((i,i+1)) \]
怎么想到的?我怎么知道。
F [To code]
下标先改为 \([0,n)\)。
借助 Lucas 定理可以得到:
- \(t \ge n\) 则 \(c\) 必然归零。
- 否则 \(c_i = \bigoplus_{j\subseteq t} a_{(i+j)\bmod n}\)。
接下来,创造性地从 \(t\) 的最低位开始考虑:
若 \(2 \mid t\) 则可以直接按奇偶分类。
若 \(2 \nmid t\) 则考虑将还原 \(a\) 的任务改为还原 \([a_0 \oplus a_1, a_1 \oplus a_2, \dots, a_{n-1} \oplus a_0]\),这同时要求全体异或和为 \(0\)。
我们 bitrev 后就有 DP,状态记录 \(t,c\) 和要求的 \(a\) 的异或和。
但这依然实现不了,但下一个观察是关于异或和这一维整个 DP 数组的形态是 trivial 的:全 \(0\)、全等于某一 \(2^k\)、有且仅有一个位置等于某一 \(2^k\)。
于是整体 DP 是容易维护的。
这样,我们就解决了 \(n = 2^k\) 的情况。
对于一般的 \(n = 2^k \cdot b\) \((2 \nmid b)\) 的情况,结论是将所有模 \(2^k\) 同余的下标异或起来得到新的 \(c'\) 数组,原问题立刻转化到 \(b=1\) 的情况。
其实不难证明,但是难以想到。
#800
A
神秘结论题。先去掉后导 \(0\),然后后缀和。
那就是第一个位置之后全都要是负的,才能走回去。
B
自底向上贪心。
C
Dijkstra.
D
猜一个条件,结论是禁子结构 \([3,4,1,2]\) 或 \([2,1,4,3]\)。
然后数据结构可以维护。
另一个做法。考虑 DP,然后可以整体计算。
因为所有时刻,同一个位置本质不同的值是 \(O(1)\) 种的。
我记得这样的套路,我在 CSP2019-S 考场上想到了。D1T2 保我第一个一等奖 /gz
E
我们知道操作必然是每次操作更小的那一边。但是并不能模拟。
考虑加速模拟,从大到小枚举权值。我们考虑在枚举到「每次操作更小的那一边」的时候对该位置进行操作,因为这个时候这个位置就变成了当前权值,符合枚举顺序。
并且最大值也恰好是枚举中第一次出现的权值。因此我们考虑打标记。
修改一个位置 \(x\),此刻我们了解到其左侧所有已经扫过的位置,在右侧的最大值一定都确定了。右侧的类似。
观察这个过程,发现仅确定左侧最大值的一定是一段前缀,仅确定右侧最大值的一定是一段后缀,都未确定的一定是一段区间。这样就不难维护了。
另一个做法。考虑计算每个位置的贡献,那么我们只关心这个元素如何变成 \(0\)。
考虑将所有值撒在数轴上,在当前值左侧的赋黑色,右侧的赋白色。那么我们每次可以走到往左看第一个黑色或白色的位置。考虑直接 DDP 即可。
F
首先猜到只需要操作 \(c_0=c_1\) 的。
不妨设总共 \(c_0 \ge c_1\),每次找一个最长的 \(c_0=c_1\) 的前缀操作,然后删掉前缀 \(0\)。若此时 \(c_0 \le c_1\) 了则可以恢复一些 \(0\) 来一次操作完成。这就是最优的。
为什么呢?小编也很好奇。
#796
A
讨论一下 \(k\) 与 \(n\) 的大小关系即可。
B
先求出边权,然后用询问来做 Kruskal。
C
令 \(s_i = \sum_{j=1}^i (a_j-b_j)\)。操作的意思就是当且仅当 \(s_{l-1}=s_r\) 的时候可以将区间覆盖为 \(s_r\)。
再注意到若在 \(s_{l-1}=s_r\ne 0\) 的时候操作是没用的,既不可能使状态更优也不可能增加有用的操作。
所以接下来用数据结构编一编就容易求解了。
D
令 \(b_i = a_i + k\),记值域为 \(V\)。
注意到当 \(b_1 = V^2\) 时直接合法,故 \(\left\lfloor\sqrt{b_1}\right\rfloor\) 只须考虑 \(V\) 种取值。
第二个观察是,如果 \(k\) 是合法的,那么在 \(\left\lfloor\sqrt{b_1}\right\rfloor\) 不变的情况下也不会改变 \(\left\lfloor\sqrt{b_i}\right\rfloor\)。这是因为凸性。
并且,令 \(x=\left\lfloor\sqrt{b_1}\right\rfloor\),若 \(a_i-a_{i-1} \le x\),则其所在的组也是一样的,故每轮可以将这样的缩起来合并计算。
这就是 \(O(n+V)\)。但是 sqrt 的常数好像有点大。
E
早就听说过。
通过 min-max 容斥我们可以转化为花费 \(2^{|S|}-1\) 的代价操作一个子序列的 \(\gcd\)。
然后可知 \(\gcd_{i\ne j} a_i a_j = (\gcd_i a_i)^2 \prod_i \frac{\gcd_{j\ne i} a_j}{\gcd_j a_j}\)。考虑质因子可知。
F
用 \(x\) 记排列长度,\(t\) 记 \(p_{i-1}+1=p_i\) 的个数,\(q\) 记 \(<\) 的个数。
来一个容斥,钦定若干个连续上升的公差为 \(1\) 的等差数列。GF 就是 \[
\sum_{i\ge 0} \sum_{j\ge 0} \left\langle\begin{matrix}i\\j\end{matrix}\right\rangle \left(\frac{x}{1-x(t-1)q}\right)^i q^j
\]
其中 \(t-1\) 来自于符号化容斥,也可以理解成二项式反演。
我们要做的就是提取其 \([x^nt^s]\)。
\[
\begin{aligned}
&= [t^s] \sum_{i\ge 0} \binom{n-1}{i-1} (t-1)^{n-i} q^{n-i}\sum_{j\ge 0} \left\langle\begin{matrix}i\\j\end{matrix}\right\rangle q^j \\
&= \left[\frac{x^{n-1}t^s}{(n-1)!}\right] \mathrm e^{x(t-1)q} \left(\frac{1-q}{\mathrm e^{x(q-1)}-q}\right)' \qquad \text{(Eulerian number)} \\
&= \left[\frac{x^{n-1}t^s}{(n-1)!}\right] \mathrm e^{x(t-1)q} \frac{(1-q)^2\mathrm e^{x(q-1)}}{(\mathrm e^{x(q-1)}-q)^2} \\
&= \left[\frac{x^{n-1}}{(n-1)!}\right] \frac{(xq)^s}{s!} \frac{(1-q)^2\mathrm e^{-x}}{(\mathrm e^{x(q-1)}-q)^2}
\end{aligned}
\]
注意前后的 \(x\) 意义并不一样。
记 \(m=n-s-1\),那么目标就变成了求 \[ [x^m] \frac{(1-q)^2\mathrm e^{-x}}{(\mathrm e^{x(q-1)}-q)^2} = (1-q)^2[x^m] \frac{\mathrm e^{x(1-2q)}}{(1-q\mathrm e^{x(1-q)})^2} \]
换元 \(u=x(1-q)\),就有 \[ = (1-q)^{m+2}[u^m] \frac{\mathrm e^{u\frac{1-2q}{1-q}}}{(1-q\mathrm e^u)^2} \]
再换元 \(w=\mathrm e^x-1\),就有 \[ \begin{aligned} &= (1-q)^{m+2} [u^m] \frac{(1+w)^{\frac{1-2q}{1-q}}}{(1-q(1+w))^2} \\ &= (1-q)^m [u^m] \frac{(1+w)^{\frac{1-2q}{1-q}}}{(1-\frac{qw}{1-q})^2} \\ &= (1-q)^m [u^m] \sum_{i\ge 0}\binom{\frac{1-2q}{1-q}}i w^i \sum_{j\ge 0} (j+1)\left(\frac{qw}{1-q}\right)^j \\ &= (1-q)^m \sum_{k\ge 0} [u^m] (\mathrm e^u-1)^k \sum_{i\ge 0} \binom{\frac{1-2q}{1-q}}i (k-i+1)\left(\frac q{1-q}\right)^{k-i} \end{aligned} \]
再换元 \(s=\frac q{1-q}\),就有 \[ = (1-q)^m \sum_{k\ge 0} [u^m] (\mathrm e^u-1)^k \sum_{i\ge 0} \binom{1-s}i (k-i+1) s^{k-i} \]
那么我们求出一行第二类斯特林数,而右侧的和式能够通过矩阵递推,于是用熟悉的分治 NTT 方法即可。
细心的观众可能会发现官方题解中的 \(x,y\) 相当于这里做换元 \(x \mapsto yx, q \mapsto x^{-1}\)。也就是做了一个系数翻转。
而在官方题解中这里通过凑出 \(\frac{\mathrm e^{u\frac{1-2q}{1-q}}}{1-q\mathrm e^u}\) 的导数将问题转化成算两次 \([u^m] \frac{\mathrm e^{u\frac{1-2q}{1-q}}}{1-q\mathrm e^u}\),大概常数要小一些。
#794
A
考虑最大最小配,但是这样可能会挂。所以我们应该尽量让权值排名的距离都不太近。配 \((i, i + n/2)\) 即可。
B
对极长的 \(\texttt{ABABABA}\dots\) 讨论。长为奇数的要优先满足,胡乱贪心即可。
C
在前缀和的最大值处翻转前后缀必定合法,于是只要看能不能只操作一次即可。
选第一次 \(<0\) 前和最后一次 \(<0\) 后的最大值判一下即可。
D [To be continued]
考虑数列 \((b_0,b_1,\dots,b_{m-1})\) 的贡献 \(\sum_{i=0}^{m-1} |b_i-b_{(i+1)\bmod m}|\) 取到最小值 \(2(m-1)\) 当且仅当 \(b\) 是连续的单调数列。
注意到 \(q_i \to p_{q_{i+1}}\) 会连出一堆环,再连接 \(q_i \to p_{q_{i}}\),整个图就(弱)连通了。
E
先来一手 Dilworth 定理,需要 \(n\) 个下降子序列覆盖原排列。
自然考虑 \(n-1\) 个长为 \(2\) 的和 \(1\) 个长为 \(3\) 的。把 \(n+2,\dots,2n+1\) 当成左括号,\(1,\dots,n\) 当成右括号,\(n+1\) 当成特殊字符。
根据 Raney 引理,我们一定能找到一个循环移位使得括号序列合法。
这个时候看一下 \(n+1\) 在不在括号里,如果在那就做完了,否则再把它旋到开头或结尾看看是否满足条件。
这个时候玩一下可以发现,\(n+1\) 在开头时只有 \(1,\dots,n\) 按顺序出现时不满足;\(n+1\) 在结尾时只有 \(n+2,\dots,2n+1\) 按顺序出现时不满足。
于是我们要判当 \(n+1\) 在开头时括号序列是否合法。如果不合法,说明它应该在括号内。这个可以通过维护前缀和判断。
否则判一下 \(1,\dots,n\),\(n+2,\dots,2n+1\) 在环上是否按顺序出现。这个可以通过维护两两距离和判断。
#789
A [Coded]
随便前缀和即可。
B [Coded]
考虑在每一行每一列第一个数处统计该行的或值,再以对应方式求和。
我比较蠢,甚至写了个按 \(m-1\) 分块,把或当半群维护的(
C [Coded]
求出环,数出 \(\sum\lfloor len/2\rfloor\),因为奇数长的环多出来那个数是没用的,不影响答案。
那么每个环上一定是 \(><>\dots<><\),我们安排小的那些数位于 \(><\) 中间,大的位于 \(<>\) 中间,于是它们的系数就固定了。
D [Coded]
\(v\) 序列与排列的双射是周知的。考虑进行一轮冒泡排序,会将 \(v\) 整体减一并左移一位。
于是计数就很平凡了。
E [Coded]
枚举 \(\max\{p_l, p_{l+1}, \dots, p_r\} = p_k\),再枚举 \(p_i \cdot p_j = p_k\),再根据 \(p_k\) 作为最大值控制的区间,可以得到若干矩形。
则询问就是一个子矩形内的面积并。
可能可以通过线段树维护历史最小值个数和解决,但注意到两个相交的矩形必有相同的左和上边界,因此可以通过单调栈转化为不交的矩形。
F [Coded]
先算系数,这个容易 DP。
接下来问题是计算 \(\sum_{j=0}^{a_i} p^j \cdot j^k\)。
接下来给出两种方法,但实质等价。
法一。设 \(F(n) = \sum_{j=0}^{n-1} p^j \cdot j^k\),差分得 \[ F(n+1) - F(n) = p^n n^k \]
注意到两侧乘 \(p^{-n}\) 就得到一个 \(n\) 的多项式,因此不妨假设 \(F(n)\) 是 \(p^n S(n) + C\) 的形式,其中 \(S\) 是多项式,\(C\) 是常数。取 \(n=0\) 可得 \(C = -S(0)\)。
因此我们有 \[ \begin{aligned} pS(n+1) - S(n) &= n^k \\ pS(x+1) - S(x) &= x^k \\ (p\mathrm e^{\mathrm D} - 1) S(x) &= x^k \\ S(x) &= \frac1{p\mathrm e^{\mathrm D} - 1} x^k \\ &= \sum_{j=0}^k \frac{k!}{(k-j)!} x^{k-j} \cdot [t^j] \frac1{p\mathrm e^t - 1} \end{aligned} \]
法二。直接使用类似伯努利数的推导,有 \[ \begin{aligned} F(n) &= \sum_{j=0}^{n-1} p^j \cdot j^k \\ &= \left[\frac{t^k}{k!}\right] \sum_{j=0}^{n-1} p^j \mathrm e^{jt} \\ &= \left[\frac{t^k}{k!}\right] \frac{p^n\mathrm e^{nt} - 1}{p\mathrm e^t - 1} \end{aligned} \]
从而显然与法一结果相同。
然后多点求值。
#783
A
枚举 \(0\),然后贪心。
B
随便优化 DP 即可。
C
如果已经删去 \(k\) 行 \(k\) 列,则剩下一个 \((n-k) \times (n-k)\) 的正方形,一共有 \(2n-2k-1\) 条对角线。
于是我们通过 \(k\ge 2n-2k-1\) 可以得到一个下界 \(\left\lceil\frac{2n-1}3\right\rceil\)。
对着这个下界构造会发现这是个确界。这里抄一张图:
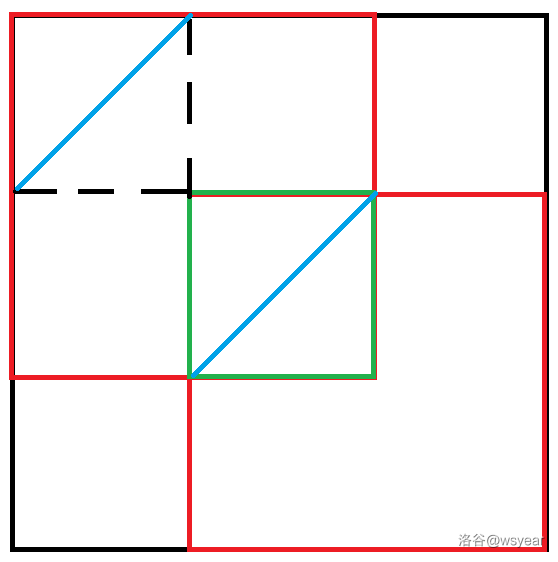
D
\((u,v)\) 相邻边数的奇偶性自然等于 \(\deg_u + \deg_v\) 的奇偶性。
自下往上枚举一条 \((u,v)\),可以知道这条边需要在 \(\deg_u\) 为奇/偶时删除。
对于一个点尝试模拟删除其儿子即可,顺便判定无解。
求出来之后,用类似的方法即可构造。
E
令 \(m=\frac{n+1}2\),则是重心当且仅当子树大小 \(\ge m\) 且各儿子 \(< m\)。注意到若只是 \(\ge m\),则重心必在其子树内,不难容斥计算。因此只需对每个 \(i\) 算出 \(i\) 子树大小 \(\ge m\) 的方案数即可。
然后 \(O(n)\) 很简单,因为没啥意思推导过程就不写出来了。
F [Not to be continued]
什么勾八构造,流汗了!!!1
#775
A
随便拆一下绝对值。
B
显然调和级数复杂度。
C
康托展开的推广。
D
线段树优化建图似乎可以 \(O(n \log^2 n)\),但是我们随便 DP 或者优化一下最短路好像就能 \(O(n\log n)\) 了。
E
好像用 Kruskal 或者 Boruvka 都能做啊,但是感觉还是 Boruvka 简单一点。
F
边三入门题(?
对于树边 \(e\),设经过 \(e\) 的路径数为 \(v(e)\),经过 \(e\) 的非树边的状态为 \(w(e)\)(我们只需要判断是否相等,因此使用 xor hash)。
答案有以下 \(4\) 种情况:
- 割两条割边 \(e_1,e_2\),答案为 \(v(e_1) + v(e_2)\)。
- 割一条割边 \(e\) 和一条其他边,答案为 \(v(e)\)。
- 割一条树边 \(e\) 和一条非树边,那当且仅当有且仅有一条非树边越过 \(e\) 时有贡献,答案为 \(v(e)\)。
- 割两条树边 \(e_1, e_2\),则必须 \(col(e_1)=col(e_2)\),否则对答案也没有贡献,答案为恰好覆盖其一的路径数。
前三种情况都随便做,讨论第四种情况,我们先来观察一些性质:
- 非树边都是祖先-后代链,因此同颜色的边也有祖先-后代关系。
- 不可能出现颜色相交,即 \(\texttt{ABAB}\),但可能有 \(\texttt{ABA}\)。因为这是类似区间染色的操作。
接下来有个 \(1\log\) 做法,但是好像比较复杂。
另一个 \(2\log\) 做法是对每种颜色做分治决策单调性。
#773
A
随便排个序匹配一下。
B
暴力匹配,是对的。
C
确定为 \(0\) 很容易,确定为 \(1\) 就要求存在一个 \(1\) 区间使得其他位置都确定为 \(0\)。
D
按 \(w\) 排序,转化为对每个 \(i\) 计算其后第一个与其不交的集合。
计算区间与 \(i\) 相交的集合数可以容斥并用 Trie 查询。
E
分治 NTT 一下。
F
首先,答案有一个上界: \[ r \le \frac 4{\sqrt{\pi}} \cdot 10^8 \cdot \frac{\sqrt{k-1}}{\sqrt l} \]
假设我们二分答案,那么也就是能选出一些圆 \(C_{i_1}, C_{i_2}, \dots, C_{i_k}\),以 \(A_{i_1}, A_{i_2}, \dots, A_{i_k}\) 为圆心,\(r\) 为半径,使得他们有交。
考虑枚举交的某个圆弧所在的圆 \(C_j\),我们转而检查 \(C_{j-l+1}, \dots, C_j, \dots, C_{j+l-1}\) 交在 \(C_j\) 上的位置中存在某个位置被覆盖至少 \(k-1\) 次。
但是 \(l\) 很大,我们考虑只要枚举 \(|A_i A_j| \le 2r\) 的点。用一个 trick,将平面按 \(2r\times 2r\) 分块,只需要枚举 \(9\) 个块里的点,如果同时保证 \(|i-j|< l\),似乎期望只要枚举 \(O(k)\) 个。然后扫描线即可。
按顺序遍历 \(j\),维护当前的 \(r\),则有一个结论是 \(r\) 期望只会变小 \(O(\log n)\) 次。
总复杂度 \(O(nk\log n+k\log n \log \varepsilon^{-1})\)。
#768
A
\(k=0\) trivial。
\(0 < k < n-1\) trivial。
\(k=n-1\),考虑拆贡献成 \(n-2\) 和 \(1\)。
B
通过一个简单的界可以算出一个答案的界,然后构造一下发现过了。
C
把每种颜色第一次和最后一次出现的位置提出来,中间的都可以贡献。
我们认为这是一些线段,那么包含的也可以先贡献掉。
然后当成覆盖问题贪心即可。
D
考虑裴蜀定理,转化为仅有一种长度,设为 \(len\)。
设 \(c_i\) 表示 \(a_i\) 最终的系数(\(\pm 1\)),设 \(f_j = \prod_{i\equiv j\pmod{len}} c_i\),则每次操作 \(f\) 会同时变化。故仅有 \(f\) 全为 \(1\) 或 \(-1\) 的状态是可达的。
DP 即可。
E
感觉数数反而比较简单……
如果不需要旋转同构,就是普及组题。
需要的话,套个 Burnside 就行。环的 Burnside 的结论都该背死了吧(x
F
发现如果有奇环则一定有长为 \(3\) 的环,所以我们考虑改成有向图,要求没有长为 \(3\) 的链,也就是每个点只有出度或者入度。
这看似是个 2-SAT,但由于整除关系是偏序,所以我们考虑转化为最长反链。
拆入点和出点,对于 \(x \mid y\),只有 \(x_o\) 和 \(y_i\) 是可以共存的。
所以我们考虑连 \(x_i \to y_o\),\(x_i \to y_i\),\(x_o \to y_o\),然后对每个 \(x\) 连 \(x_i \to x_o\)。这一定是没环的。然后算最长反链(最小链覆盖)即可。
#767
A [Coded]
贪心,贪心,贪心。
B [Coded]
显然最多选两个,随便讨论一下。
C [Coded]
观察观察,发现系数有点规律。
D [Coded]
DP 式是容易的,格路计数的组合意义也是容易的。
E [To code]
建出 Kruskal 重构树,然后众所周知点集的 LCA 等于 DFS 序最小和最大点的 LCA。
F [Not to be continued]
谔谔,估计咕掉了。
#755
A
求出对称差,做完了。
B
算出 \(i\),然后用逆序对作差可以求出 \(i\) 的位置上是几,同理可得 \(j\) 的位置上是几。
C
条件是对任意 \(l \le i \le r\) 都有 \(a_i + a_{i-2} + \dots - a_{i-1} - a_{i-3} - \dots \ge 0\),且区间内奇偶位置上的数的和相等。
不难维护。
D
状态设某个字母,是每个串中第几个,然后转移不难。
E
考虑到线段距离 \(\le R\) 的范围是不好做的,但是相对于每个 \(p_k\),考虑作一个半径为 \(R\) 的圆,则过 \(p_i\) 的两条切线和过 \(p_j\) 的两条切线互相 bound 对方。
F
操作分块,缩缩点,恒河里。
#752
A
枚举判断,因为 LCM 是很大的,所以不会枚举很多次。
B
若 \(x > y\),则 \(n=x+y\) 满足条件。
否则,我们考虑把 \(\bmod\) 当成 \(-\) 来做。可以发现 \(y-x < x\) 时 \(n=\frac{x+y}2\) 是满足条件的。
而注意到 \((kx,y)\) 的解一定是 \((x,y)\) 的解,这样就可以将任意情况归约到上述情况。
C
从后往前,尽可能平均地拆分即可。根据数论分块,我们知道状态数是 \(O(\sum \sqrt a_i)\) 的。
D
首先段数超过 \(\log_2 n\) 后就不用做了,答案一定是 \(n\)。
如果用线段树优化转移就是 \(O(n\log^3 n)\),直接跑分治决策单调性就是 \(O(n\sqrt n +n\log^2 n)\)。
E
排序后只要判区间,进一步只要判前缀。
枚举 \(a_1\),考虑从大到小记搜,能直接冲过去。
F
itst /ll
\(x=0\) 很经典。\(x\ne 0\) 答案一样,计算每种向量组能表出的数的个数,枚举秩即可。
#751
A
答案显然是各位上 \(1\) 的个数的公约数。
B
优化一下 BFS 即可。
C
\(b\) 肯定要按升序插入,然后对每个 \(b_i\) 维护一下插入每个位置的代价贪心即可。
D
有一个贪的做法,就是按 \((\max(a,s),s)\) 排序后直接按顺序贪。
有一个没那么贪的做法,按 \(a\times s\) 排序后线段树优化 DP(主要是对于 \(a \le s', a' > s\) 要求 \((a,s)\) 在 \((a',s')\) 前)。
有一个比较 DP 的做法,按 \(a\) 排序,DP 操作序列的前缀最大值,也可以线段树优化。
E
按模 \(k\) 分类,单调栈随便做就行。
F
先取逆,然后 Meet in the middle,感觉其实也不是特别难。
#745
A
枚举上下边界,类似最大子段和。
B
c9 /ll c9 /ll c9 /ll
DP 笛卡尔树。
C
根号分治思博题。
D
这么神秘的式子一看就有神秘组合意义,假设 \(b_1 < b_2 < \dots < b_m\),注意到这就是 \[ \sum_{i=1}^m \sum_{j=i+1}^m (a_{b_i} + a_{b_j} - 2\min(a_{b_i},a_{b_{i+1}},\dots,a_{b_j})) \]
放到笛卡尔树上,等价于两两距离和。
转为算边的贡献,树上背包即可。
E
先求出最短路 DAG,然后考虑使得每个点有至少 \(2\) 个入度。
可以看出如果没有修改操作,存在一个贪心做法。
对于修改操作,我们时间倒流使得区间覆盖可以均摊掉,然后维护一下即可。
F
对于 \(2\mid n\),取 \(b_{2k} = a_{2k}, b_{2k+1} = m-1-a_{2k+1}\),则只需计数 \(b_1 \le b_2 \ge b_3 \le \cdots \ge b_{n-1} \le b_n \ge b_1\)。
选一种符号容斥即可。
对于 \(2\nmid n\),按 \(\left\lceil\frac m2\right\rceil\) 分段,则只是每个对象变成了链。
#446
A [Coded]
如果有 \(1\) 直接输出。否则找一个最短且互质的连续段。
B [Coded]
考虑直接将权值安排一个错排,比如移一位。
C [Coded]
按权值从小到大加入所有边,对于一种权值,先对每个询问做,然后撤回。
D [Coded]
考虑枚举删的边,那么只需求每条边两侧的子树中删去一个点的方案数,使得剩下的点存在完美匹配。
先不管换根,考虑子树内。设 \(f(u,0/1,0/1)\) 表示 \(u\) 子树内,\(u\) 是否已匹配,除了 \(u\) 之外还有 \(0/1\) 个点还未匹配的选点方案数。
转移时,考虑先将每个儿子 \(v\) 接到 \(u\) 上(即假设仅保留 \(u\) 点和 \(v\) 点的子树),然后将各子树合并。
对于合并的过程后两维的变化,我们可以写出乘法表:\(0 \otimes 0 = 0\),\(0 \otimes 1 = 1 \otimes 0 = 1\),\(1 \otimes 1\) 未定义。
这可以看成两个元素的子集卷积,或者是 \(\bmod x^2 y^2\) 的卷积。也就是说,这是交换、结合的。
可惜不一定可逆,不过我们仍然可以直接换根。
E [Coded]
众所周知,这个贡献是 \(\prod a_i\) 之差。因此我们只要算出最后 \(\prod a_i\) 的期望。
采用 EGF,我们考虑一个 \(i\) 的所有操作的贡献: \[
F_i(x) = \sum_{j\ge 0} \frac{(a_i-j)(x/n)^j}{j!} = (a_i - x/n) \mathrm e^{x/n}
\]
则答案就是 \(\prod_{i=1}^n a_i - [x^k/k!] \prod_{i=1}^n F_i(x) = \prod_{i=1}^n a_i - [x^k/k!] \mathrm e^x \prod_{i=1}^n (a_i - x/n)\)。
容易做到时间复杂度 \(O(n^2)\)。如使用分治 MTT,可以做到 \(O(n\log^2 n)\)。